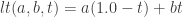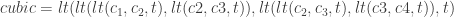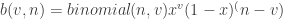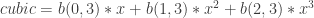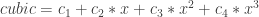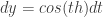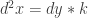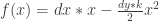The backend for Blender’s sculpt system is a simple coarse bounding volume hierarchy, which we call PBVH. It’s a KD-tree that uniquely assigns vertices to leaf nodes. To access node vertices we have a rather hideous C macro, BKE_pbvh_vertex_iter_begin. All of this had lead to a code pattern that’s fairly verbose with lots of copy-and-pasting of code. For example, here is is the code for the smooth brush (scroll down for the improved version):
static void do_smooth_brush_task_cb_ex(void *__restrict userdata,
const int n,
const TaskParallelTLS *__restrict tls)
{
SculptThreadedTaskData *data = static_cast<SculptThreadedTaskData *>(userdata);
SculptSession *ss = data->ob->sculpt;
Sculpt *sd = data->sd;
const Brush *brush = data->brush;
const bool smooth_mask = data->smooth_mask;
float bstrength = data->strength;
PBVHVertexIter vd;
CLAMP(bstrength, 0.0f, 1.0f);
//Copy and pasted code block!
SculptBrushTest test;
SculptBrushTestFn sculpt_brush_test_sq_fn = SCULPT_brush_test_init_with_falloff_shape(
ss, &test, data->brush->falloff_shape);
//Copy and pasted code block!
const int thread_id = BLI_task_parallel_thread_id(tls);
AutomaskingNodeData automask_data;
SCULPT_automasking_node_begin(
data->ob, ss, ss->cache->automasking, &automask_data, data->nodes[n]);
BKE_pbvh_vertex_iter_begin (ss->pbvh, data->nodes[n], vd, PBVH_ITER_UNIQUE) {
//Copy and pasted code!
if (!sculpt_brush_test_sq_fn(&test, vd.co)) {
continue;
}
//Copy and pasted code!
SCULPT_automasking_node_update(ss, &automask_data, &vd);
//Copy and pasted code.
const float fade = bstrength * SCULPT_brush_strength_factor(
ss,
brush,
vd.co,
sqrtf(test.dist),
vd.no,
vd.fno,
smooth_mask ? 0.0f : (vd.mask ? *vd.mask : 0.0f),
vd.vertex,
thread_id,
&automask_data);
if (smooth_mask) {
float val = SCULPT_neighbor_mask_average(ss, vd.vertex) - *vd.mask;
val *= fade * bstrength;
*vd.mask += val;
CLAMP(*vd.mask, 0.0f, 1.0f);
}
else {
float avg[3], val[3];
SCULPT_neighbor_coords_average_interior(ss, avg, vd.vertex);
sub_v3_v3v3(val, avg, vd.co);
madd_v3_v3v3fl(val, vd.co, val, fade);
SCULPT_clip(sd, ss, vd.co, val);
if (vd.is_mesh) {
BKE_pbvh_vert_tag_update_normal(ss->pbvh, vd.vertex);
}
}
}
BKE_pbvh_vertex_iter_end;
}
static void SCULPT_smooth(
Sculpt * sd, Object * ob, Span<PBVHNode *> nodes, float bstrength, const bool smooth_mask)
{
SculptSession *ss = ob->sculpt;
Brush *brush = BKE_paint_brush(&sd->paint);
SculptThreadedTaskData data{};
data.sd = sd;
data.ob = ob;
data.brush = brush;
data.nodes = nodes;
data.smooth_mask = smooth_mask;
data.strength = bstrength;
TaskParallelSettings settings;
BKE_pbvh_parallel_range_settings(&settings, true, nodes.size());
BLI_task_parallel_range(0, nodes.size(), &data, do_smooth_brush_task_cb_ex, &settings);
}
What we want is something that’s more readable (and C++), something more like this:
void SCULPT_smooth_new(
Sculpt * sd, Object * ob, Span<PBVHNode *> nodes, float bstrength, const bool smooth_mask)
{
SculptSession *ss = ob->sculpt;
Brush *brush = BKE_paint_brush(&sd->paint);
blender::editors::sculpt::exec_brush(
ob,
nodes, nullptr,
[&](auto &range) {
for (auto &vd : range) {
const float fade = bstrength * vd.falloff;
if (smooth_mask) {
float val = SCULPT_neighbor_mask_average(ss, vd.vertex) - *vd.mask;
val *= fade * bstrength;
*vd.mask += val;
CLAMP(*vd.mask, 0.0f, 1.0f);
}
else {
float avg[3], val[3];
SCULPT_neighbor_coords_average_interior(ss, avg, vd.vertex);
sub_v3_v3v3(val, avg, vd.co);
madd_v3_v3v3fl(val, vd.co, val, fade);
SCULPT_clip(sd, ss, vd.co, val);
if (vd.is_mesh) {
BKE_pbvh_vert_tag_update_normal(ss->pbvh, vd.vertex);
}
}
}
});
//}
}
This is much better. But the challenge doesn’t stop with writing a cleaner task API.
Task Boundaries
We need to choose a good boundary for task splitting to efficiently use all CPU cores. Splitting tasks by PBVHNodes can be highly inefficient since the nodes themselves are too large to make good task boundaries. Oftentimes only one or two nodes will be under the user’s brush cursor.
The proper solution is to make leaf nodes smaller (this would also speed up ray casting quite a bit). Unfortunately GPU meshes live in leaf nodes, which limits how small we can make them.
The stopgap solution I implemented was to put all the verts in the nodes under the brush cursor into an array and then pre-filter it to throw out any that lie outside the brush; that way I can use any task grain size I want. Unfortunately while this is quite a bit faster in many cases if the user zooms out and applies the brush on the entire mesh (or is working with a particularly dense mesh) it becomes slower.
For this reason exec_brush is implemented with two back-ends, one that splits parallel tasks by nodes and another that builds a flat vertex list. This is why the main exec callback is a generic lambda, to facilitate the use of multiple iterator implementations.
Per-Node Custom Data
Often times when writing brushes you want to attach data to PBVHNodes. You might also want to do something to a list of nodes prior to the main execution task. This can be done via a special user-provided struct:
void SCULPT_smooth_new(
Sculpt * sd, Object * ob, Span<PBVHNode *> nodes, float bstrength, const bool smooth_mask)
{
SculptSession *ss = ob->sculpt;
Brush *brush = BKE_paint_brush(&sd->paint);
struct MyNodeData {
bool modified = false;
};
blender::editors::sculpt::exec_brush<MyNodeData>(
ob,
nodes,
/* Create per-node data. /
[&](PBVHNode *node) {return MyNodeData()},
[&](auto &range) { /* Main exec lambda. */
for (auto &vd : range) {
/* We have various options to thread-safely update
* node_data->modified. The safest is to make it an int
* and use atomics. Note that x86 has implicit
* atomic stores, but of course we might be
* compiling on ARM. */
vd.node_data->modified = true;
}
},
[&](PBVHNode *node, MyNodeData *node_data) {
if (node_data->modified) {
/* Do something to node. */
}
})
}
PBVH Types and PBVHNode Vertex Iterators
Even though we have this nice high-level task interface, we still need an iterator for accessing PBVHNode vertices. This is not as easy as it looks since Blender’s sculpt mode actually has three different back-ends: one for simple meshes (PBVH_FACES), one for multires (PBVH_GRIDS) and one for dynamic topology (PBVH_BMESH). But thanks to the magic of templates it’s not too hard, either.


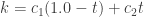
 ,
,  are constants and
are constants and  is a point on the curve in parameter space (It’s actually a bit more useful to use a cubic polynomial for curvature, but that’ll come later).
is a point on the curve in parameter space (It’s actually a bit more useful to use a cubic polynomial for curvature, but that’ll come later).
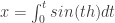

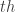 can be integrated analytically, but
can be integrated analytically, but  and
and  must be integrated numerically. This isn’t terribly difficult on modern computers, especially since there’s a pretty easy to trick to integrating any arc-length-parameter plane curve.
must be integrated numerically. This isn’t terribly difficult on modern computers, especially since there’s a pretty easy to trick to integrating any arc-length-parameter plane curve.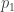 and
and 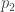 , and two curvature points, the point
, and two curvature points, the point